Prerequisites
Before you can use AI Generator, you must properly configure a connection within Connect AI. For more information about configuring a connection, see Sources. You can select any of your pre-made connections that are inside of AI Generator to query.AI Generator
To access the generator, click AI Generator on the top right of the Data Explorer page.
1
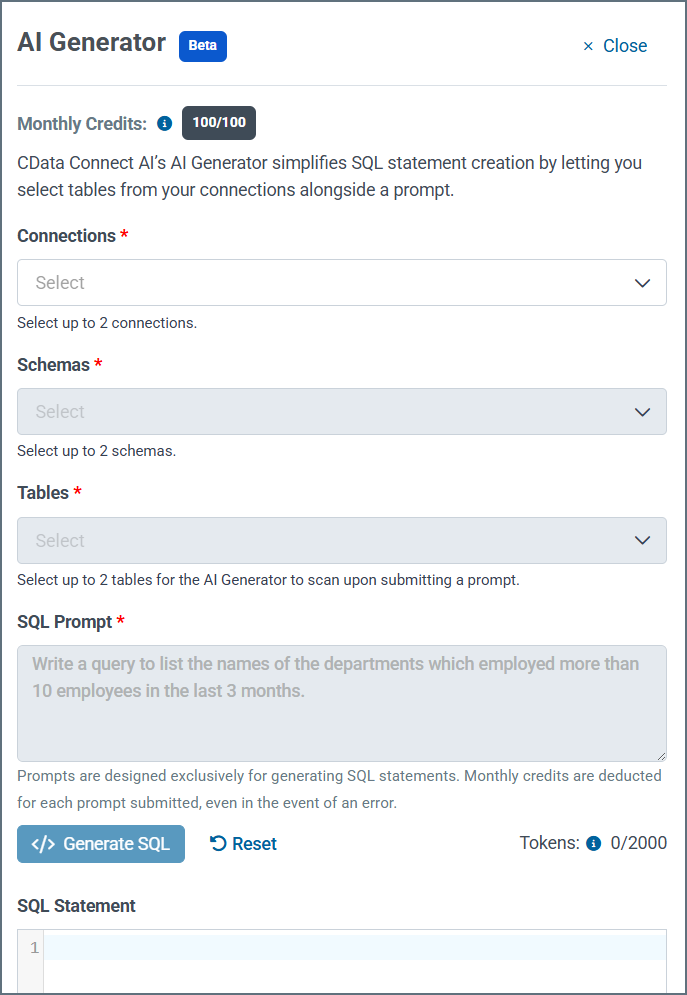
Select Connect AI connections from the Connection list (up to two connections).
2
Select the schemas that you are interested in querying from the Schemas list (up to two schemas). Note that if you select one connection and there is only one schema in that connection, AI Generator selects that schema automatically.
3
Select the tables that you are interested in querying from the Tables list (up to two tables).
4
Enter a plain text description in the SQL Prompt text box to describe the query that you want to execute on the data.
5
Click Generate SQL. The SQL statement that is generated by AI appears in the code box.
6
Click Execute. The query is copied into the data explorer’s SQL box. You can also click Copy to copy the SQL query and paste it manually.
7
Click Execute again to run the query on the data. The result appears underneath the data explorer SQL box.
Secure Query Generation
After you select your connection, the tables available in that connection populate the Tables list. The plain English that you enter is bundled with the metadata (only column names) of the tables you selected and is sent to a Microsoft Azure OpenAI endpoint as a prompt. For security reasons, no data beyond this metadata is transmitted to Azure. The service generates a SQL query and returns it to Connect AI. Once the SQL is generated, the metadata is discarded.Tokens
Large Language Model (LLM) algorithms transmit data to their models by translating the characters in the request into tokens. By calculating the tokens that are required, Connect AI judges the complexity of the request and the processing power that is needed to complete it. In general, a token consists of four characters.
The model has a per-minute processing capacity. If multiple users send requests simultaneously, the service might stall or need extra time to transmit a response.